智能空战
1.训练架构
1.x 数据格式说明
1.x.1 step函数输入输出
-
actions(输入):[线程,智能体,动作(4维或5维)]
-
obs:[线程,智能体,状态(15维)]
-
rewards:[线程,智能体,奖励(1维)]
-
dones:[线程,智能体,结束标志(1维)]
1.x.2 buffer中存储的数据(8维)
- obs:同上
- actios:同上
- rewards:同上
- masks:[线程,己方智能体,mask(1维)]
- action_log_probs:[线程,己方智能体,probs(1维)]
- values:[线程,己方智能体,value(1维)]
- rnn_states_actor:[线程,己方智能体,网络层数,神经元个数(通常128维)]
- rnn_states_critic:[线程,己方智能体,网络层数,神经元个数(通常128维)]
2.评价指标
这里引入elo机制来评价己方智能体的策略。
2.1 elo机制
2.1.1 elo机制原理
elo机制是一种衡量竞技类比赛选手实力的评分系统,被广泛用于游戏行业,其核心在于通过竞技比赛逐渐计算出选手的实力得分。
ELO算法给每个参与者一个评分,也就是elo分数,在游戏中被叫做隐藏分。
ELO算法基于假设:一名选手当前实力受各种因素影响在真实实力附近波动,某时刻其实力的函数应当符合正态分布,其中表示选手的实力平均水平,表示实力的稳定性:
设为两名选手的ELO分差,两名选手对战时的预期胜率可以表示为,其含义可以由图表示。

由于积分不利于运算,通过最小二乘法可以得到与它图像相近的函数
最后的迭代公式为
其中是玩家比赛结束后的新排位分值,是比赛前玩家的排位分,是一个加成系数,由玩家分支水平决定(分值越高越小),是玩家实际对局结果得分(赢=1,输=0)
2.1.2 智能空战中的elo机制应用
在智能空战中要应用此公式,主要是针对对局结果得分的规定。本方案利用奖励来作为评估胜利失败的条件。
智能空战训练中,每一次策略网络更新后都会进行一次策略评估。策略评估就是用最新策略与历史策略池中选择随机选择一个策略进行一次完整的对抗,会得到己方和敌方奖励值,根据奖励值差值大小评估为胜利、平局和失败。

2.2胜率
将当前模型与策略池中的某个模型进行100次对局,根据奖励值差值大小评估为胜利、平局和失败。并以此来计算胜率。
实验设置采样时运行60个线程,设置buffer大小为3000,那么需要走18万步开始一次策略更新,根据图表显示,180万步时开始收敛,即第10代智能体已经收敛了。
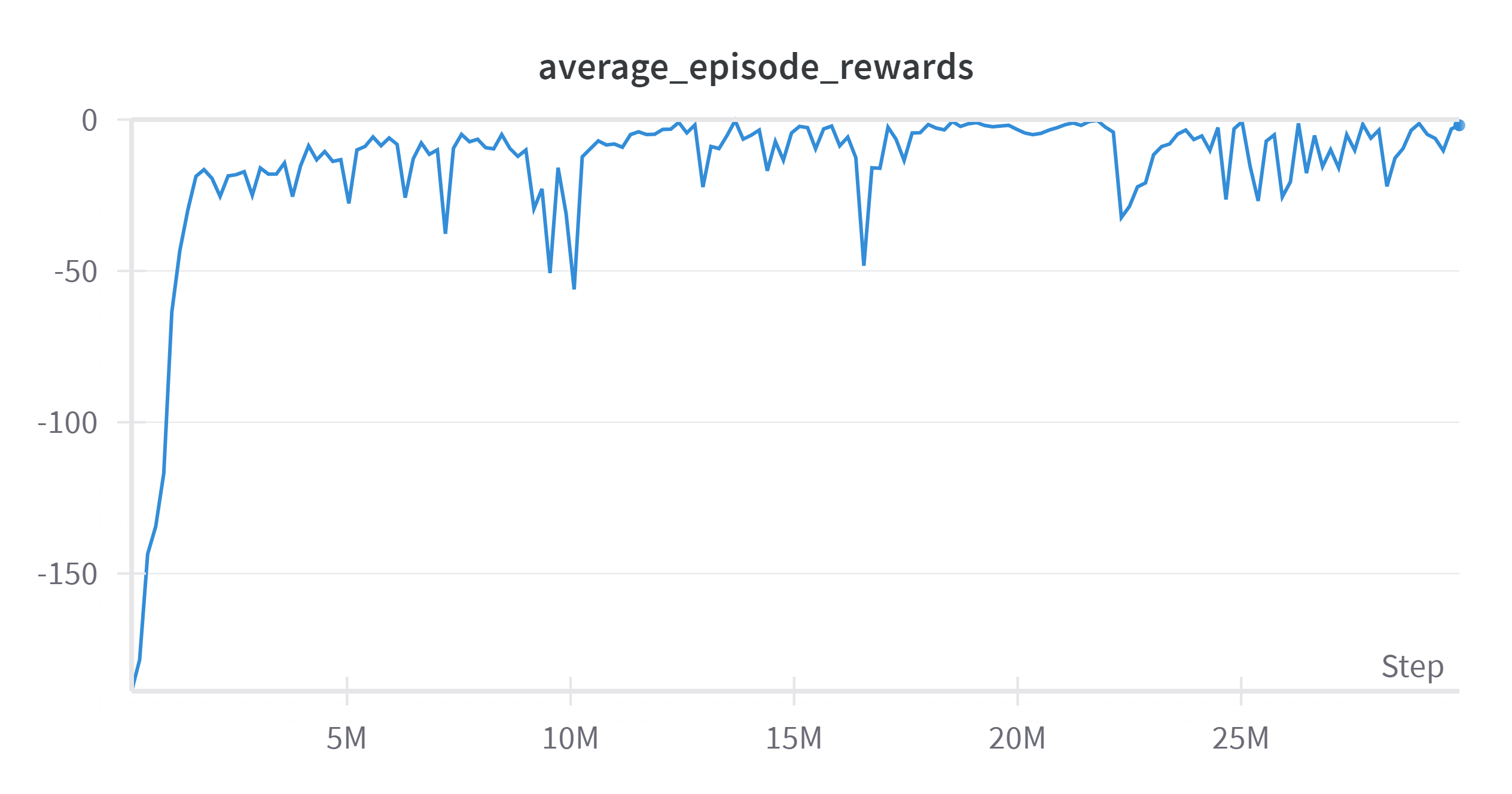
而策略评估过程的智能体在大约522万时开始收敛,即第29代智能能提开始趋于平稳,在后续由于循环策略的原因,导致后续评估过程不再稳定。
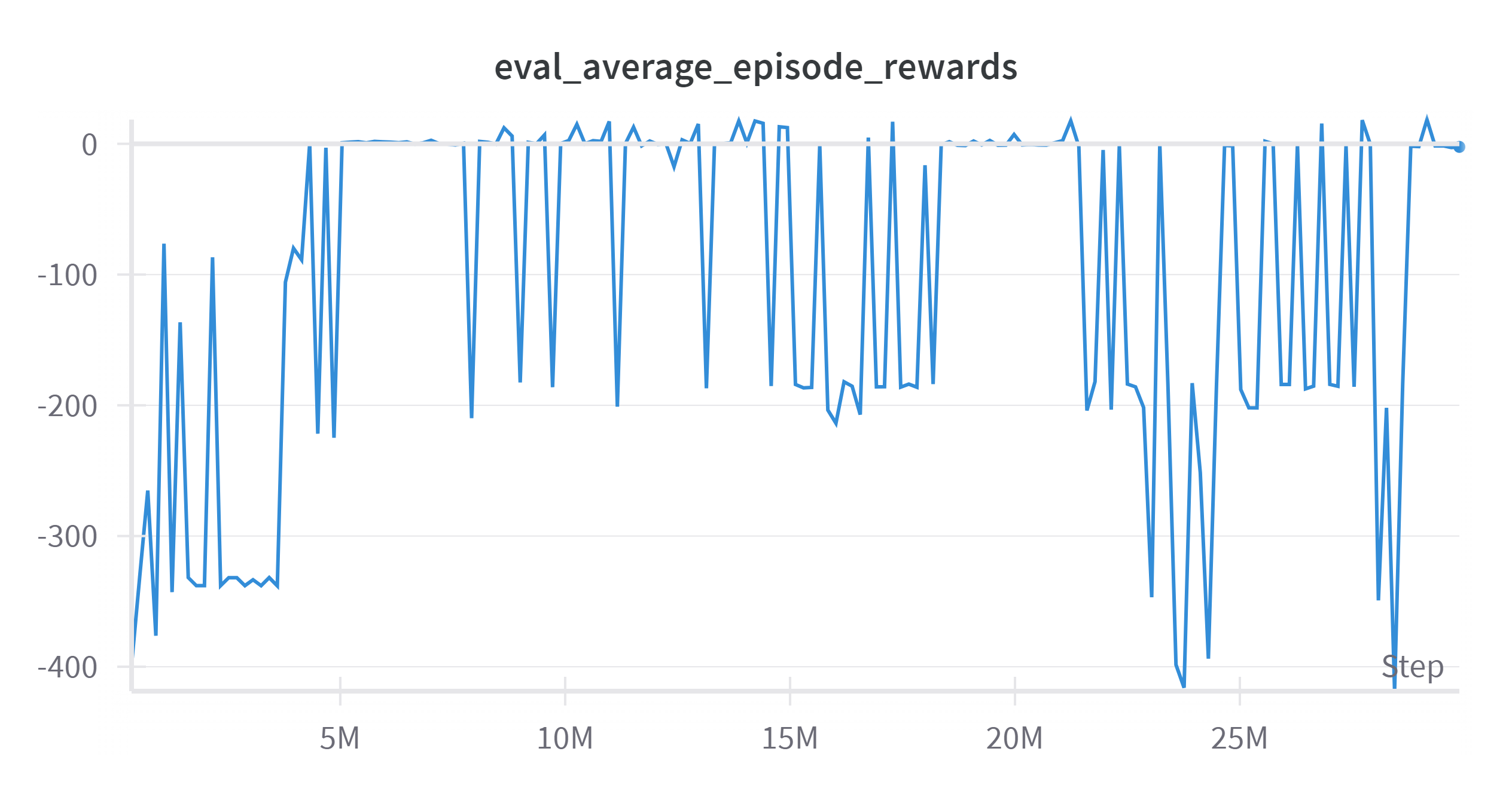
3.后续改进计划
3.1后续策略被挑选次数少和策略非传递性问题
由于最初策略池中策略稀少,前几代的策略被选择的次数远大于后面添加的策略,导致对后面的策略胜率大幅降低。

策略非传递性就是策略,,但是,在强化学习训练中的体现就是,挑选策略2作为对手进行网络更新后,导致对本来已经训练很好的策略1反而对抗能力降低了。从游戏角度上说,比如一个职业玩家在跟大量的同等级玩家进行对抗过程中训练出了良好的预判能力,突然与一个新手玩家进行对抗,由于新手的轨迹不再常规。那么职业玩家的预判能力反而会导致错误的决策。
解决思路
首先随机选择策略是必须考虑的,因为存在策略非传递性,必须把每个敌对策略加入到策略池中。
1.由于问题主要出于策略池更新过程太快了,新策略还没有完成对当前策略池中所有策略的制胜,就已经添加新的策略进入策略池中,这也是导致策略评估过程中后期不稳定的因素。所以选择通过放缓策略池更新过程,针对当前策略池多更新几次,再添加新策略进入策略池中。
2.但是由于策略池随着策略更新不断增长,导致每个对手被挑选到的概率都在减小,导致了一种雨露均沾但是效果都不良好的情况。所以采用在挑选对手上进行改进,不再使用随机选择的方法,根据每个对手的胜率来挑选对手,尽量挑选。

3.2胜率评估效率问题
目前胜率计算还只是单进程工作,仿真器频率60HZ,每12步进行一次决策,那么决策频率5hz,一场完整的战斗设置为最大1000次决策,也就是200s时间,用100次战斗计算胜率用时20000s=333min,也就是计算跟某一代策略的胜率需要最大5h,从我目前运行过程平均几十分钟。
编写多进程程序。
3.3奖励设置问题
在观看战斗回放过程中,观察到飞机的战斗对于我想要达到的目标,击毁敌机并没有执行得特别好
考虑在前期用稠密奖励学习基本技能,后期逐渐稀疏完成最终目标。



