雷达信号处理
理论不如实践,将项目中的图整理一下放上去来直观理解理论
1.距离徙动和keystone变换
下图是一个物体在运动时,由于速度过快跨越了多个距离门。
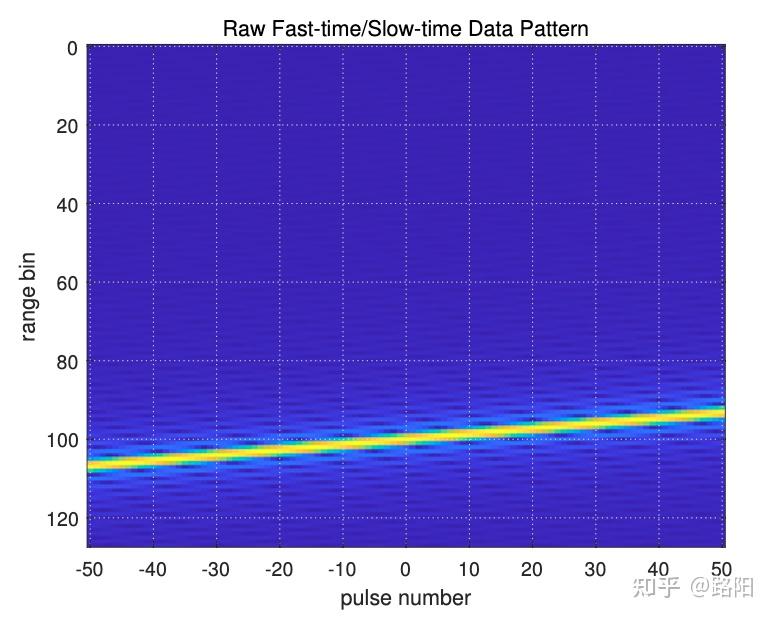
从而导致下图中距离速度图像散焦的情况,无法精确定位物体的速度和距离究竟是多少。
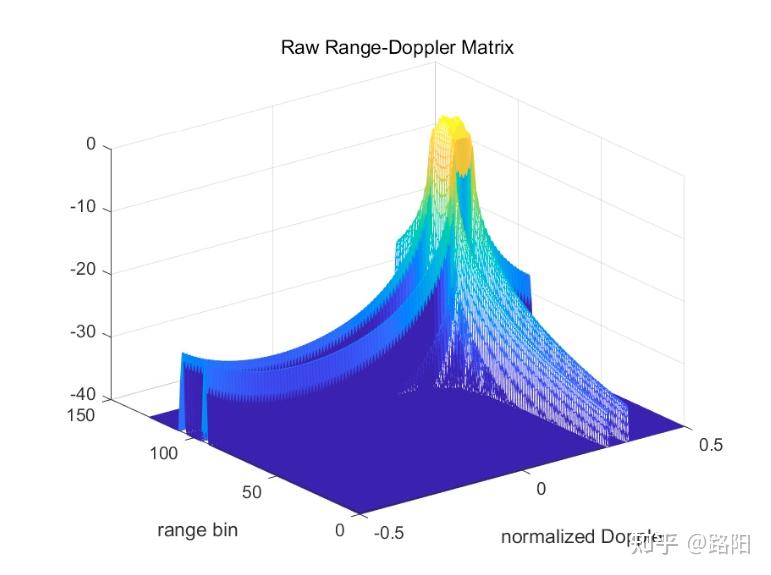
针对调频连续波信号模型,回波的快时间的FFT表示如下,可见距离频域和速度之间有乘积耦合。
keystone变换即是,从而使得雷达回波的相位中,距离和速度分离开,消除了耦合。
但是该运算量过大,一般采用CZT方法来进行keystone变换。
2.DBT框架
DBT在时间上累积观测,提高信噪比,再进行跟踪。
相对应的TBD,对原始数据直接处理,处理的信息再进行累积,不需要进行数据关联。
3.相参积累
就是多个雷达脉冲之间相位关系一致,可以累积多个脉冲提高信噪比。
多个脉冲重复周期、且统一距离单元的回波信号叠加起来。
4.CFAR检测
做二维FFT变换得到RD图,分别得到距离和速度。
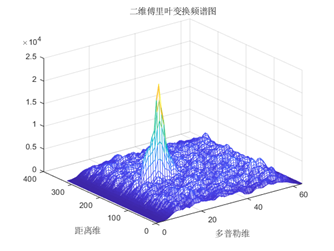
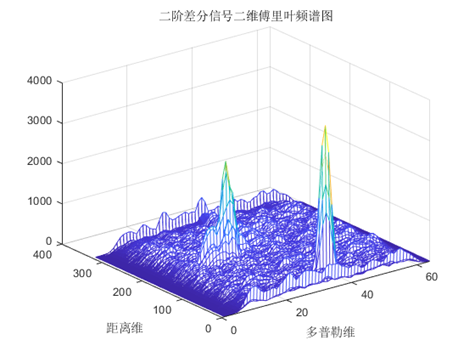
有的目标淹没在了杂波当中,先做差分再进行傅里叶变换得到新的目标。
通过CFAR检测可以得到很多张目标信息图
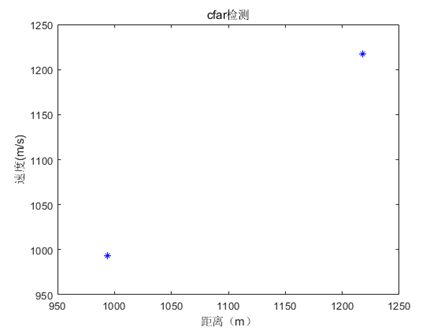
但是一般会有很多杂波点,真实目标点周围的点更多一些,所以可以通过聚类方法来确定真实目标的位置。
4.概率数据关联和扩展卡尔曼滤波
目标的航迹量测信息通常包括雷达假目标、真目标、噪声点,需要对这些点进行融合。概率数据关联就是给每个点赋予一个关联概率,根据时间累积迭代这些概率值,融合的量测就将所有测量值按比例使用得到加权测量。
融合了量测信息同样也可以融合状态估计信息,用扩展卡尔曼滤波融合状态估计信息从而得到下一位置的航迹。
智能空战AI
1.符合openai-gym接口的拟真空战仿真引擎
要应用强化学习解决问题最重要的东西就是仿真器,为此openai开发了大量的便于强化学习研究的仿真器平台,就叫做openai-gym,顾名思义就是强化学习的健身房嘛。
为了方便强化学习研究,他们制定了统一的接口,让我们可以把这个仿真器当作黑盒来使用,不用在乎内部细节。由于他们做得比较好,这些接口规范也成为了行业内的统一规范。也就是如果想要在一个自己开发的仿真器上部署强化学习算法,都必须打造成openai-gym形式,留几个接口出来。
这些接口主要是:
- reset():重置环境,返回初始状态
- step(action):执行动作,返回新的状态、奖励、是否结束、额外信息
- 状态空间定义,动作空间定义(这个有openai规定的数据格式,跟传统的int,float这些不同,有Box,Discrete)
- close():关闭环境
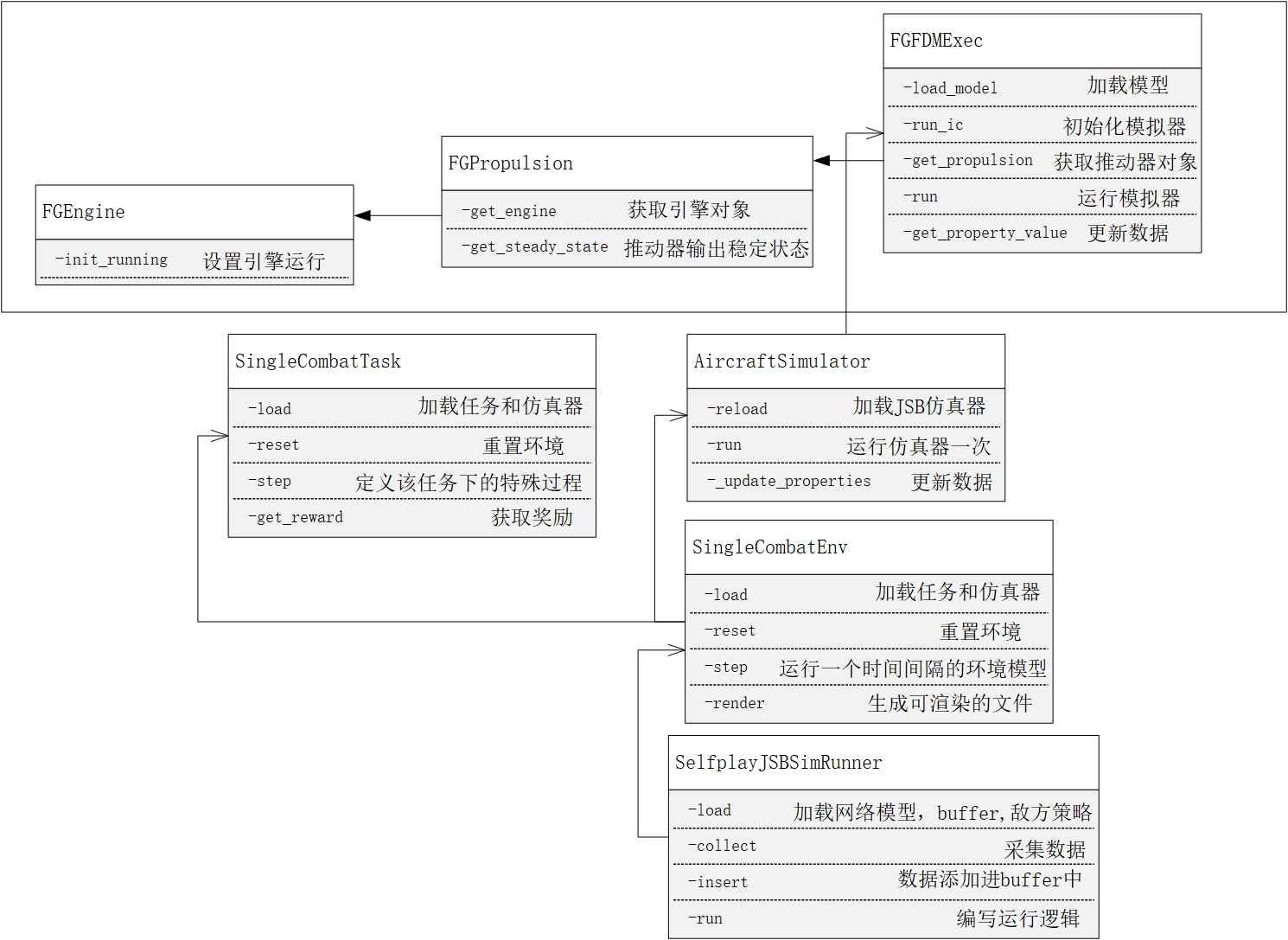
然后搭这个仿真器的时候就主要查看JSBSim的官方API文档,导出教程找到正确启动的方法之后,就采用面向对象的思想开始一步一步封装。
- 最底层:飞行器仿真器类:主要负责加载飞行器数据和调用JSBSim的API保证飞行器各个引擎运行。
- 第2层 空战环境:这里首先设置了一个基类,写了很多虚函数,通过继承实现单机控制环境、单机博弈环境和多机博弈环境。通过调用飞行器仿真器类,实现openai-gym接口
- 第3层:任务类:也是先设置一个基类,通过继承实现追逐任务、射击任务多机格斗任务这些,主要负责奖励函数,状态动作的定义这些。
- 第4层:运行类:主要负责运行过程的参数设置,强化学习中的训练策略也在这里编写。
2.LSTM,PPO,ELO,Master-Worker架构
无人集群AI
1.全局战场空中霸权争夺
根据查阅军事新闻总结出的一个观点,空中霸权争夺就是将敌方无人机全部消灭,完全控制空中战场。
2.多头注意力机制和单位导向流
因为多无人机观测到的信息很多,只需要着重于其中一些跟敌方有关的信息,所以通过多头注意力机制来提取关键信息。然后单位导向流是为了可变动作空间设计的,探测到的敌方无人机数量是可变的,但是神经网络的接口是不变的,所以就根据每个敌方无人机分别进行神经网络推理得到相应的Q值(Q就是动作价值,针对每个对手都有3个动作价值,分别是不同的子策略),然后将结果汇总起来,选择最大的Q值作为对手和子策略选择(这里得到的是一个二维Q表,选择最大的那个就能得到相应的行列,行就是对手,列就是战术)
QMIX算法是多智能体强化学习的SOTA算法,主要是针对奖励分配的。一般来说团队协作得到的都是总体奖励,比如输或者赢,但是有些lazy-agent虽然啥都没做但是得到了正向奖励,那他就会更加觉得自己合理了。所以就产生了这类价值分解的算法,最开始用线性值分解,认为总奖励是通过各个智能体奖励的线性叠加得到的,最后还是神经网络大法好,QMIX用神经网络来进行值分解,效果更好。
3.多机协同
多机协同就是多个无人机协同工作,完成一个任务,比如拦截敌方无人机,或者进行编队飞行。



