编写多进程程序完成胜率计算
使用进程池技术,给每个进程分配一个环境进行胜率计算。其架构如下图所示。

在实际运行中只有第一个进程抢到任务,其他的都直接失败
最终发现原因是因为任务中添加了读写文件的函数,由于某个进程单独占用IO,其他进程无法使用而出错。最后去掉去掉io操作,再主进程中统一读写文件。
最后运行过程如下图,可以看到cpu利用率确实占满了,但是按照我之前预估,每个100次战斗实验用时平均30分钟,一共做大约100次这样的实验,用28个cpu预计需要2个小时,但是这次用了接近两天,说明并行计算的代码还是有点问题:
于是我用同样的设备运行单进程版本的代码,发现运行一个对抗场景就已经需要一半的cpu参与运算。
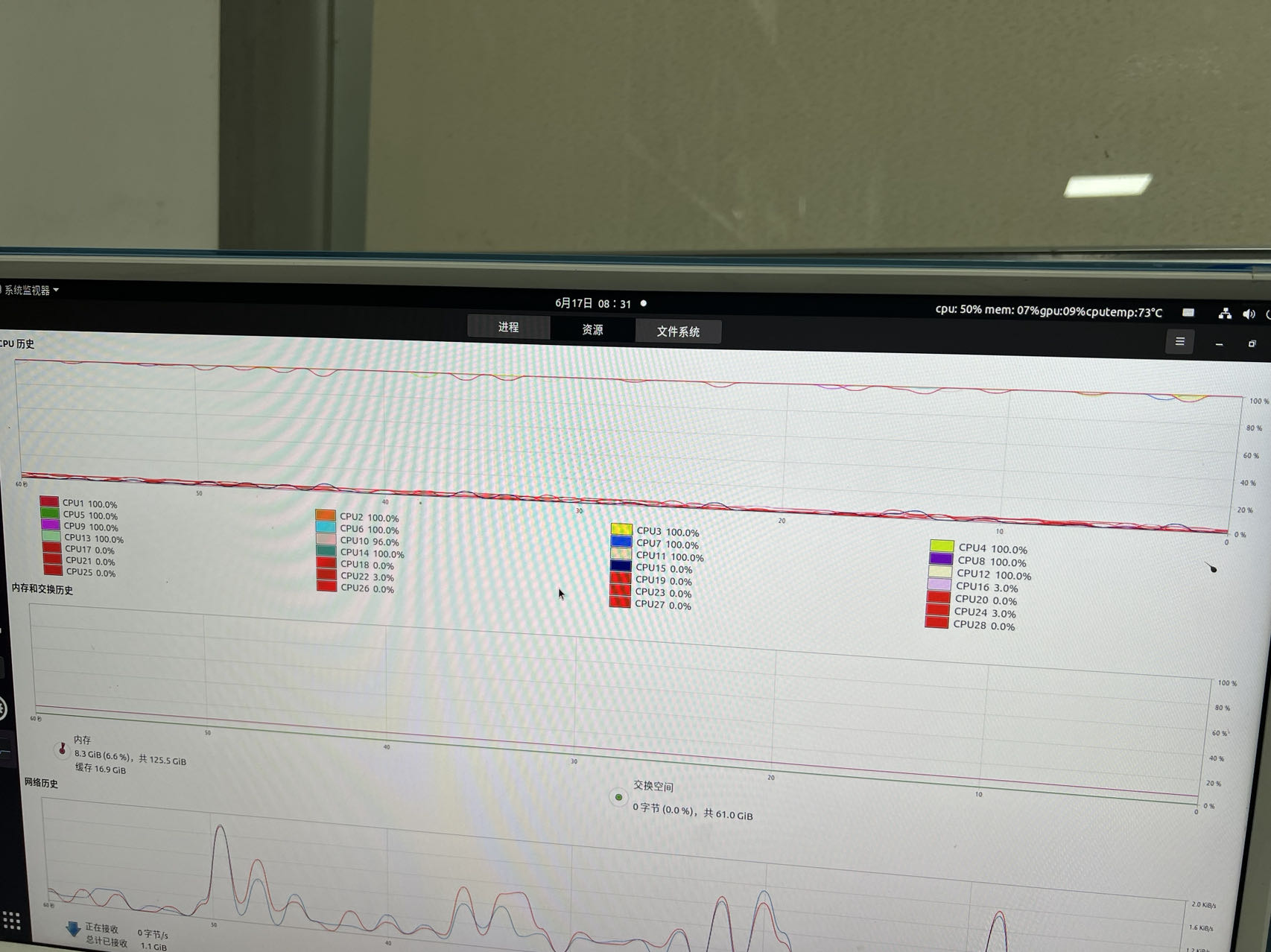
一次胜率计算的运行总时长为22分钟,
核心代码介绍
- 创建一个进程池
pool = Pool()- 编写任务
def caculate_task(ego_agent, enm_agent):
return [(ego_agent, enm_agent),win_rate]- 给进程池中添加任务
for ego_agent in range(5,15):
for enm_agent in range(0,ego_agent):
multi_res.append(pool.apply_async(caculate_task, (ego_agent,enm_agent)))- 主进程阻塞
pool.close() #关闭pool,使其不再接受新的任务
pool.join() #主进程阻塞- 获取结果
for res in multi_res:
result.append(res.get())实验结果
由实验结果可以得出,
- 己方智能体对敌方第2,3代有很高的胜率,说明了对前几代智能体被挑选次数多,被训练的效果好。
- 己方第7代智能体对前6代智能体都能够很好制胜。(不太理解)
- 第一代智能体(就是还没有经过训练的初始版本)由于并没有加入到策略池中,所以对抗时胜率并不理想,后续第2,3代都达到了很高的胜率。
- 单看同一行,可以得出由于遗忘机制(策略的非传递性),在训练的后期,对同一策略的胜率反而在逐渐减小。

一些思考
在之前的组会老师的意见和各种对强化学习吐槽基本上都会落在奖励函数的玄学调参上。所以我思考了一下为什么强化学习在奖励函数的设定上这么麻烦,为什么要进行调参这个选项。

1.为什么奖励函数没有通用的公式?
首先按照我之前写的强化学习架构来看,其实真正的奖励函数只有一个,就是达成最终目标。但是这个目标一般很难达成或者是非常模糊,意味着这个奖励是及其稀疏的,所以需要通过奖励重塑这个技巧来加快强化学习的学习速率。
那么奖励是如何重塑的呢?是通过专家知识,比如下图中教练可以通过他的经验来给出过人和投篮对于胜利是有帮助的,而且投篮进球的帮助是远胜于其他的。

那么专家知识来源于哪儿?来源于人脑。我认为人脑在一定程度上也是一个黑盒模型,比如一个战斗机飞行员可以很清楚地明白自己在什么状态下处于什么态势,应该做什么决策?但是你让他描述一下具体是什么态势值,这个态势值怎么计算,他可能需要去读个博士然后在根据自己地经验进行总结分析,才能勉强得到一个近似地评估模型。所以具有可解释性的大脑模型是非常稀缺的,可解释的程度一般是一种模糊态。

举个例子:
对于一个飞行员来说,他做决策时主要依靠两个网络,一个时决策网络,一个时态势网络,也就是军事上常用OODA环所提到的态势评估然后决策执行。态势在强化学习领域被称为状态价值,也就是当前状态能够得到的平均奖励值。

当然飞行员的态势网络和决策网络已经训练好了,现在就是需要通过态势网络反推出奖励值。由于人脑的特性,态势网络的输出本身就是一个模糊的值,以此来构造奖励模型就更加难以准确。

也就是说对于空战来说,飞行员会觉得飞行器指向敌机是一种比较好的态势,与敌机保持某个距离范围是也是一个不能忽视的态势,但是这两种态势具体哪个更重要,不同状态对应的态势值应该是多少并不清楚,所以在奖励函数设定上也只能根据这两种态势的主观感觉和实验试错来调出来。
然后我突然有个想法,既然奖励模型这么难以建模,那我能不能用神经网络来代替呢?但是仔细想想,环境给一个状态和动作,奖励模型给出一个奖励作为反馈,我要训练他,我就得给一个更精确的奖励值,本来我估计的奖励值就是不精确的,我用不精确的值作为标签取训练一个网络,然后再用这个不准确的网络去训练另一个网络,很明显就不正确。
2.RLHF是怎么做的?
之前一直听说chatGPT用到了大名鼎鼎的RLHF(基于人类反馈的强化学习)技术,听名字感觉像是用人去代替奖励模型,由于人力成本太大,我一直以为他是利用的客户在是用AI时填问卷或者别的什么机制去捕捉奖励信号。
前段时间我大致调研了chatGPT,chatGPT是闭源的,但是OPENAI官方发布了他们大致的技术路线。openai官网
其技术路线主要包括4个步骤
- 1.用GPT技术进行无监督学习[1]。
- 2.监督微调SFT
- 3.训练奖励模型RM
- 4.强化学习微调
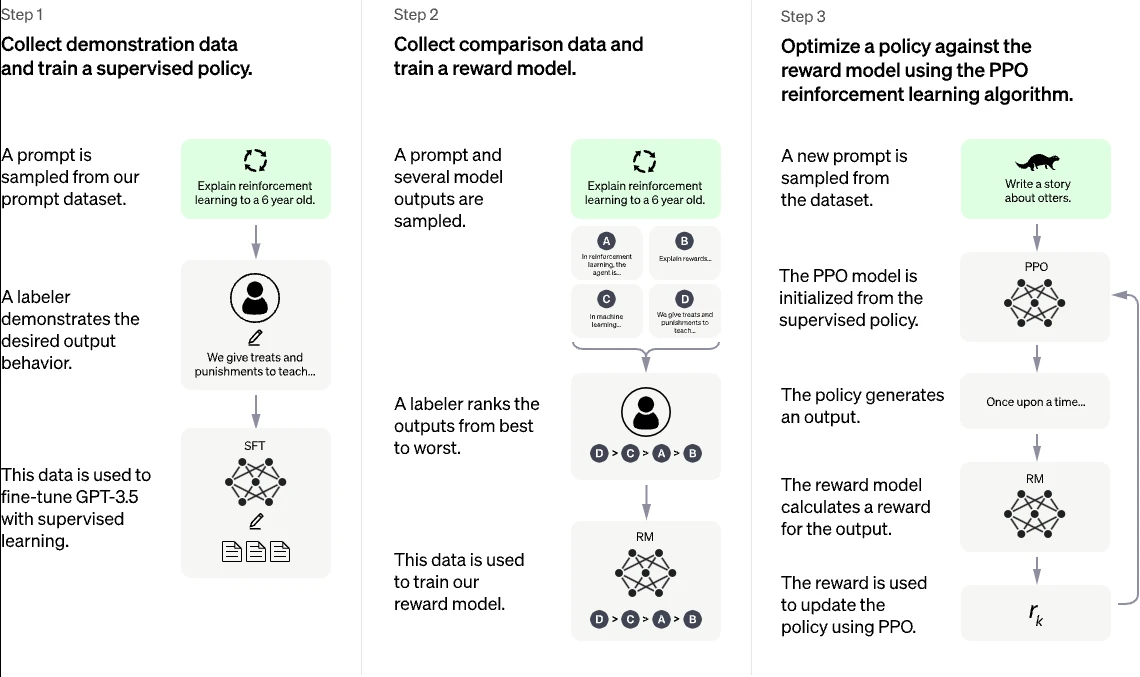
比较让我感兴趣的是,他们就是用了神经网络来拟合奖励模型。就刚刚我所想的,很多人类其实对自己人脑决策的模型并不理解,所以无法得出一个量化的指标,但是GPT利用了人脑可以对排序问题却能准确的一致。比如对于飞行员来说,他可以模糊地得出机头指向敌机尾部要比机头指向敌机头部态势要更好。所以OPENAI的做法是让GPT对一个问题生成N个回答,然后用奖励模型对每个回答进行评分,然后人类对每个回答的准确度进行排序,那么自然而然地奖励模型的目标函数就是让排序后的回答相互之间的距离和最大。GPT通过人类排序的几万条数据完成了对奖励模型的训练,然后再用这个奖励模型配合PPO算法对GPT进行训练。
GPT生成多个回答,奖励模型对每个回答得出一个评分,人类对所有回答进行排序(因为人类对于回答的评分标准不同,但是排序通常能统一选出最优秀的回答)。[2][3]

通过计算每个回答之间的质量差值
其中表示对于问题,回答与回答之间的评分差值。显然根据人类排序,这个差值应该是越大越准确,假设有k个回答,总的loss值为
其中,为人类排序后的数据集,为GPT的其中一个回答,为优选回答。其中K为回答总数。
对loss进行取反,那么神经网络的目标函数就是让这个loss最小化,让差值最大化。
但是对于我这个问题,其实还是没能解决,问题主要是我不是专家,我无法对生成的空战状态进行排序,但是我想到了一种可能性,我不是专家,也找不到军事领域的专家,但是GPT在收集了这么多数据的情况下其实可以算个半个专家了,那么我就可以通过GPT对我生成的空战数据进行排序来训练我自己的奖励模型。
还有另一种方法就是用已有的态势评估方法来作为我的奖励函数,但是能完全符合我的场景的态势评估方法可能并不多,而且可能也不准确。



