1.动机
2.1总体架构
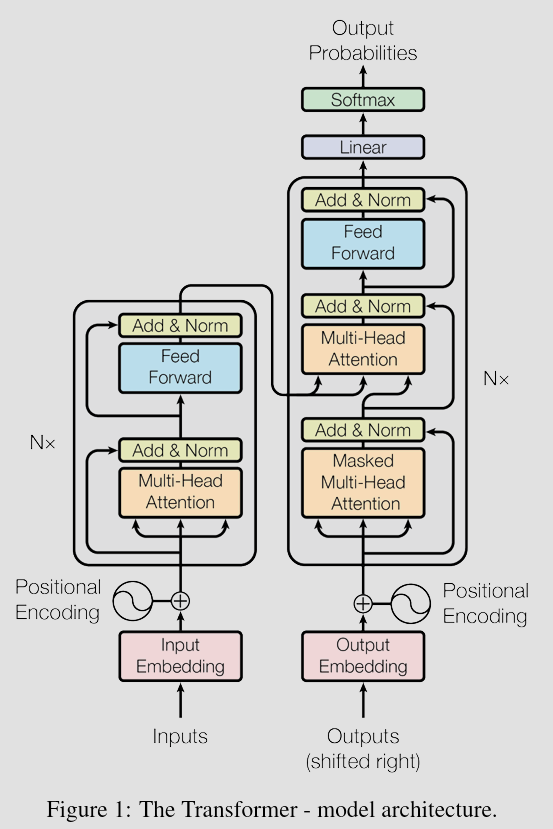
如图所示,transformer首先将输入进行Word Embedding编码,然后通过位置编码加入位置信息。后续部分分为N个编码器和N个解码器。
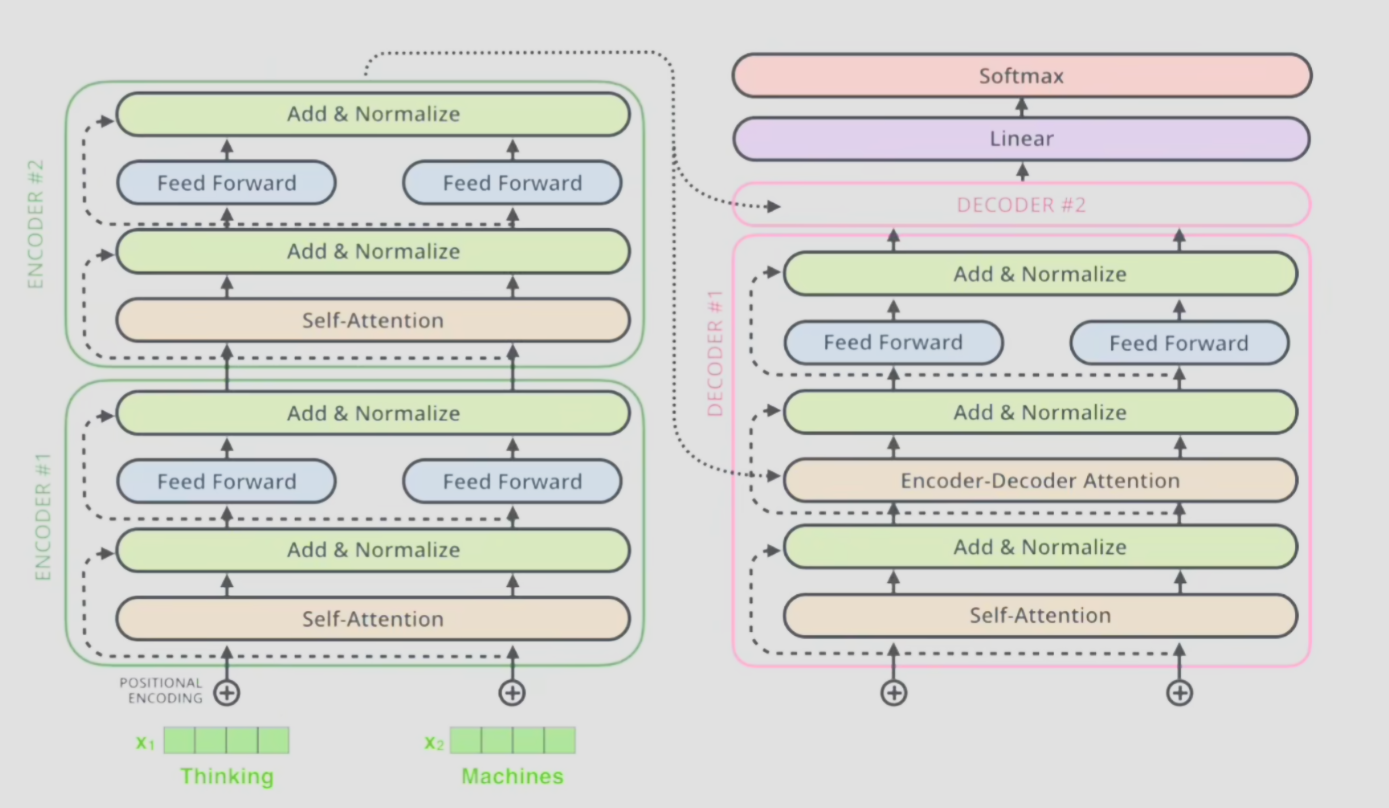
编码器内部由多头注意力机制和前馈神经网络组成,解码器内部也由前馈神经网络和多头注意力机制组成,但是加入了过去输出编码后通过掩膜多头注意力机制的输入。解码器输出的结果经过线性层和softmax得到最后的输出结果的概率。
2.1.1 Word Embedding(词嵌入)
由于神经网络能接受的输入只能是数字,所以需要一种方法将单词进行编码。如下图所示

词嵌入就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量,且将其映射到一个低维、连续的向量空间。
如图所示,将单词作为token(最小语义单元),对how,are,you分别进行编码,如果认为每个单词之间都没有任何关系就可以采用独热编码,N个单词编码为N个维度中互不相交的向量。但是显然单词之间是有关系的,如下图
那么如何初始化这些词向量的值具体可以选择随机初始化或者word2vec方法(用神经网络去预测上下文来学习词嵌入)。方法关系如下图

2.1.2 位置编码
transformer不像RNN那样一个词一个词的输出,而是通过位置编码来加入位置信息。
ppos,2ippos,2i+1=sin(100002i/dpos)=cos(100002i/dpos)
其中,pos表示token在序列中的位置,i表示位置向量里的第i个元素,d表示嵌入维度。
之所以用正余弦函数,因为其线性性质和周期性(相对位置重要性)。
设位置嵌入矩阵为P,词嵌入矩阵为E,则输出X=X+P。
2.1.3 编码器
2.1.3.1 多头注意力机制

首先是子注意力机制计算,注意力汇聚公式如下
f(q,K,V)=i=1∑nα(q,k)v
其中,q为查询,(K,V)为键值对,α(q,K)为注意力权重。

采用注意力评分函数a()对查询和键之间进行建模。
α(q,ki)=softmax(a(q,ki))
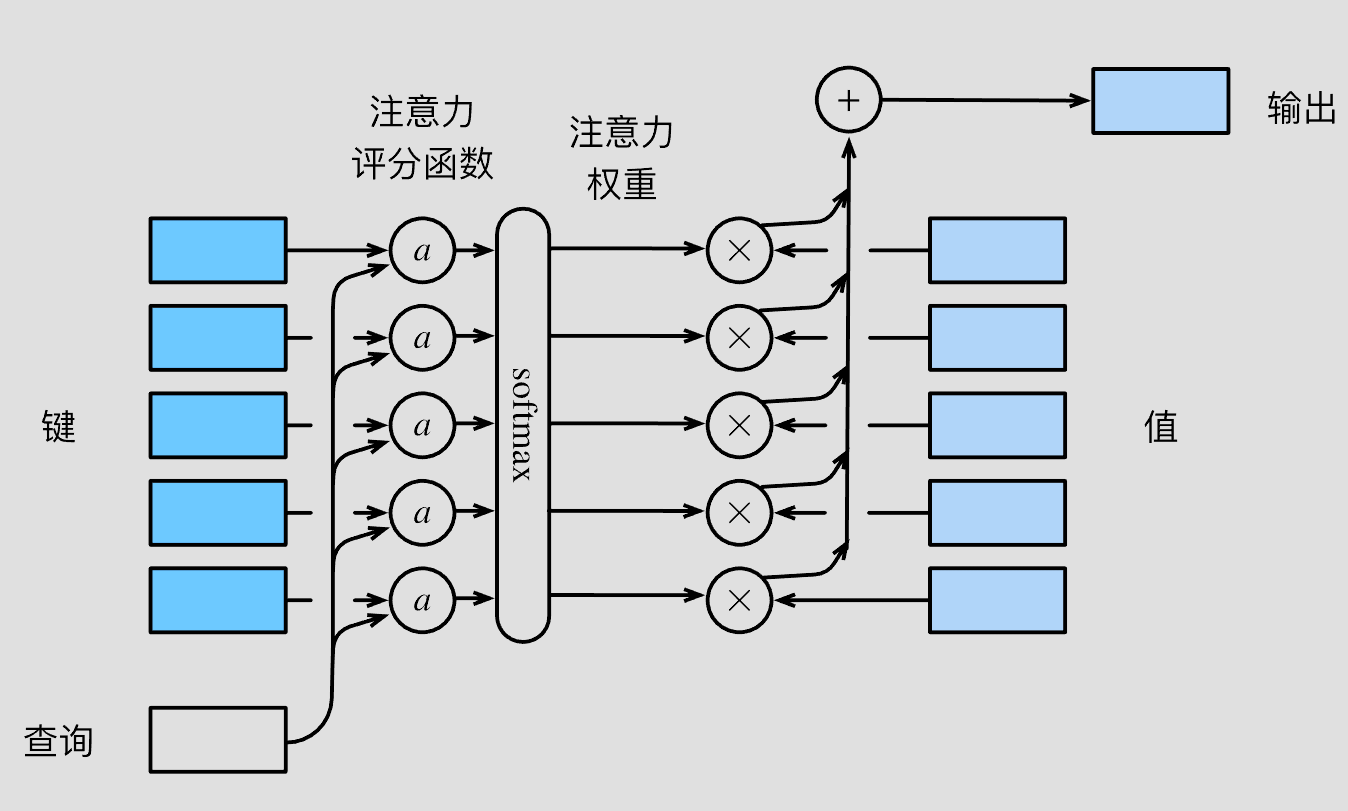
在transformer中的注意力权重计算公式如下。
Attention (Q,K,V)=softmax(dkQKT)V
在transformer中采用自注意力机制的思想得到QKV。

然后将所有得到的注意力输出连接起来进入一个线性层得到一个最终的值就是多头注意力机制。
MultiHead(Q,K,V)=Concat( head 1,…, head h)WO where head i=Attention(QWiQ,KWiK,VWiV)
2.1.3.2 残差和LayNorm
- 残差网络
引入resnet的思想(残差网络)为了让网络可以做深。

如图,有A,B,C,D个网络
XDin =XAout +C(B(XAout ))
根据后向传播的链式法则,
∂XAout ∂L=∂XDin ∂L∂XAout ∂XDin
由此可以得到
∂XAout ∂L=∂XDin ∂L[1+∂XC∂XDin ∂XB∂XC∂XAout ∂XB]
即使括号中第二项出现梯度消失,也能让该网络的梯度能够维持在第一项的水平。
- Layer Normalization
对每层的输出进行归一化,使训练更加稳定。
2.1.3 解码器

- 掩膜注意力机制
注意到译码器下方输入的结果,在训练过程中如果把所有的输出都输入到注意力机制中,那么就会导致模型看到未来的信息,这是不合理的。因此,在训练过程中,需要将当前位置之后的信息进行掩膜,使其无法参与计算。
- 与编码器交互
编码器生成K,V矩阵,解码器生成Q矩阵。

2.2实践
3.总结
编码器可以帮助解码器关注输入中的适当词汇。
解码器将先前输出的列表作为输入,以及包含来自输入的注意力信息,让解码器决定哪个编码器输入是相关的焦点,
为了防止解码器查看未来的标记,采用Mask来掩盖。
4.参考资料
[1] Transformer从零详细解读
[2] 超强动画,一步一步深入浅出解释Transformer原理!
[3] 直观解释注意力机制,Transformer的核心
[4] 动手学深度学习
[5] 【Transformer模型】曼妙动画轻松学,形象比喻贼好记
[6] 原始论文



