参考谭升的博客
并行计算和计算机架构
并行计算
并行计算设计到
- 计算机架构(硬件):为软件提供更快的计算速度,更低的性能功耗比,硬件结构上支持更快的并行。
- 并行程序设计(软件):使用当前的硬件压榨出最高的性能,给应用提供更稳定快速的计算结果。
并行性
把一个程序可以分为指令并行和数据并行
CUDA非常适合数据并行分为下面两步:
块(block)划分:将一整块数据切成小块,每个小块划分给一个线程.,每个块顺序随机周期(cycle)划分:线程按照顺序处理相邻的数据块,每个线程处理多个数据块
计算机架构
划分不同计算机架构的方法很多,广泛使用的一种被称为佛林分类法(Flynn’s Taxonomy),根据指令和数据进入CPU的方式分为四类
- SISD:单指令流单数据流(传统串行计算机,386)
- SIMD:单指令流多数据流(并行架构,比如向量机,现在CPU基本都有这类向量指令)
- MISD:多指令流单数据流(少见)
- MIMD:多指令流多数据流(现代计算机,比如GPU)
为了提高并行的计算能力,从架构上要实现下面的性能提升:
- 降低延迟:操作从开始到结束所需要的时间,一般用微秒计算
- 提高带宽:单位时间内处理的数据量,一般用MB/s或者GB/s表示
- 提高吞吐量:单位时间内成功处理的运算数量,一般用gflops来表示(十亿次浮点计算)
计算机架构也可以根据内存划分
- 分布式内存的多节点系统:通常叫集群,每个机箱都有内存处理器等硬件,通过网络互动
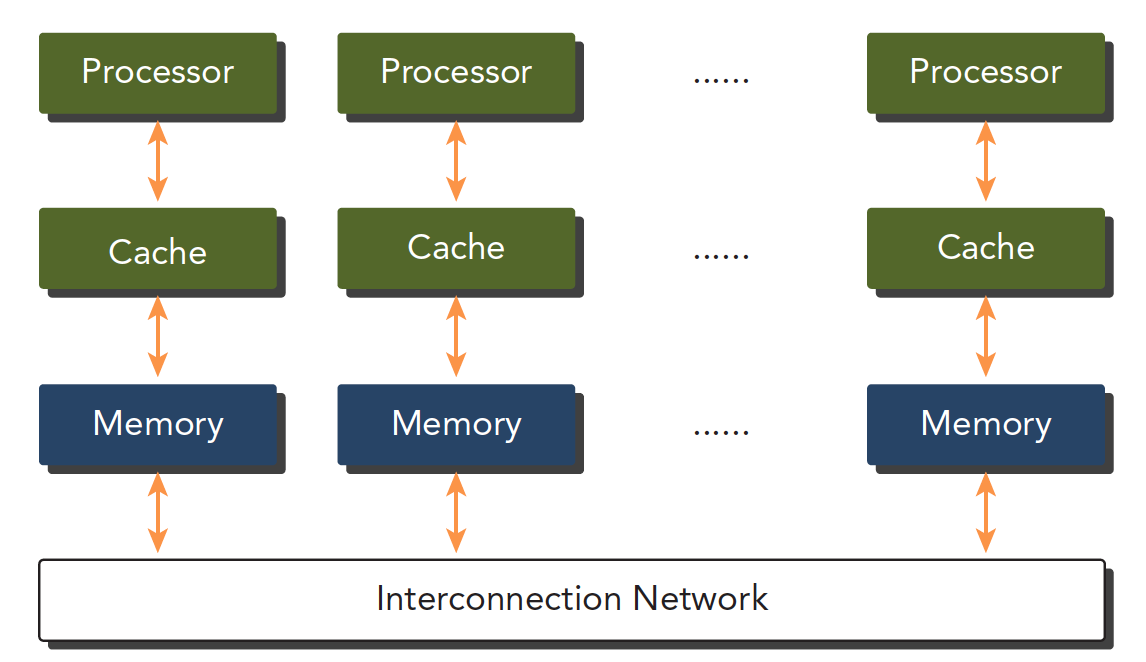
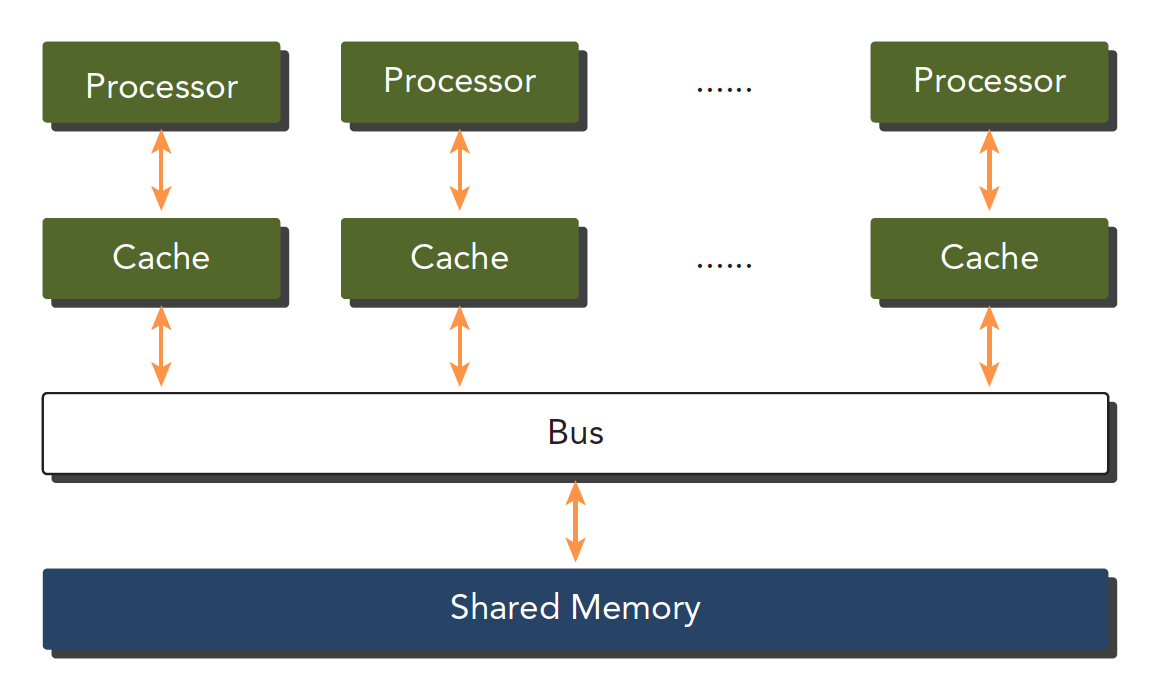
- 共享内存的多处理器系统:但个主板有多个处理器,共享主板上的内存,内存寻址空间相同,通过PCIE和内存互动.(GPU就属于这种架构)
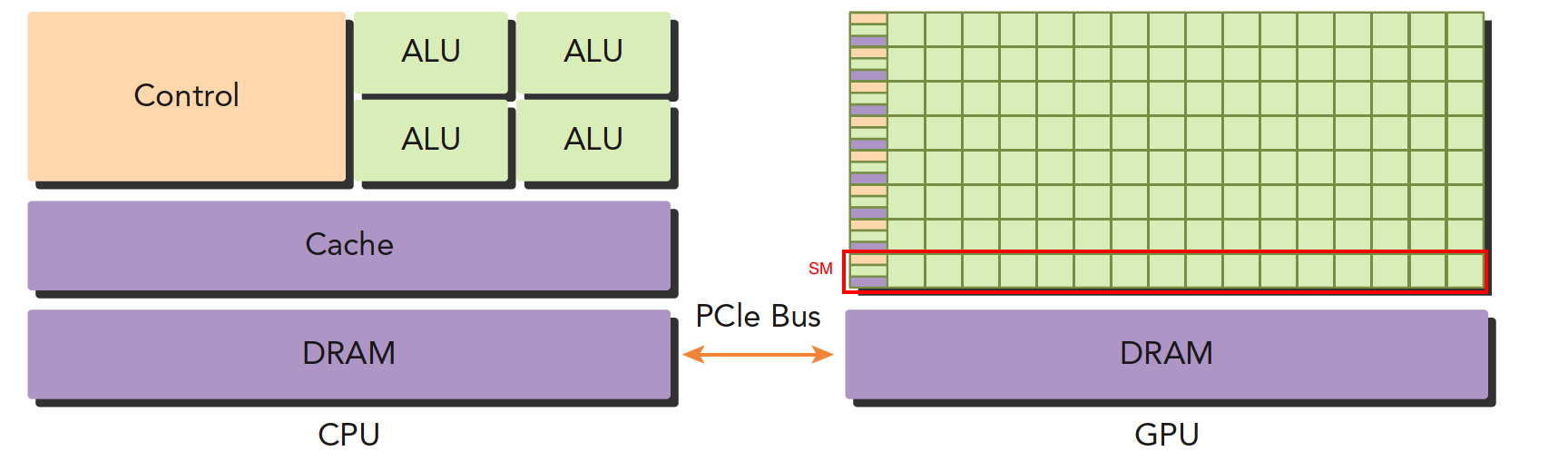
异构计算和CUDA
x86CPU+GPU是最常见的,也有CPU+FPGA,CPU+DSP等各种各样的组合.
CPU和GPU之间通过PCIE进行通信.
根据下图
- 左图:一个四核CPU一般有4个ALU,完成逻辑运算,通过总线访问内存(DRAM)
- 右图:GPU有大量ALU(绿色小方块),红色框为
流处理器(SM),每个SM内的alu公用一个control单元和Cache.
对于CPU,计算能力提升了,控制能力减弱了,所以逻辑复杂的程序不适合用GPU.
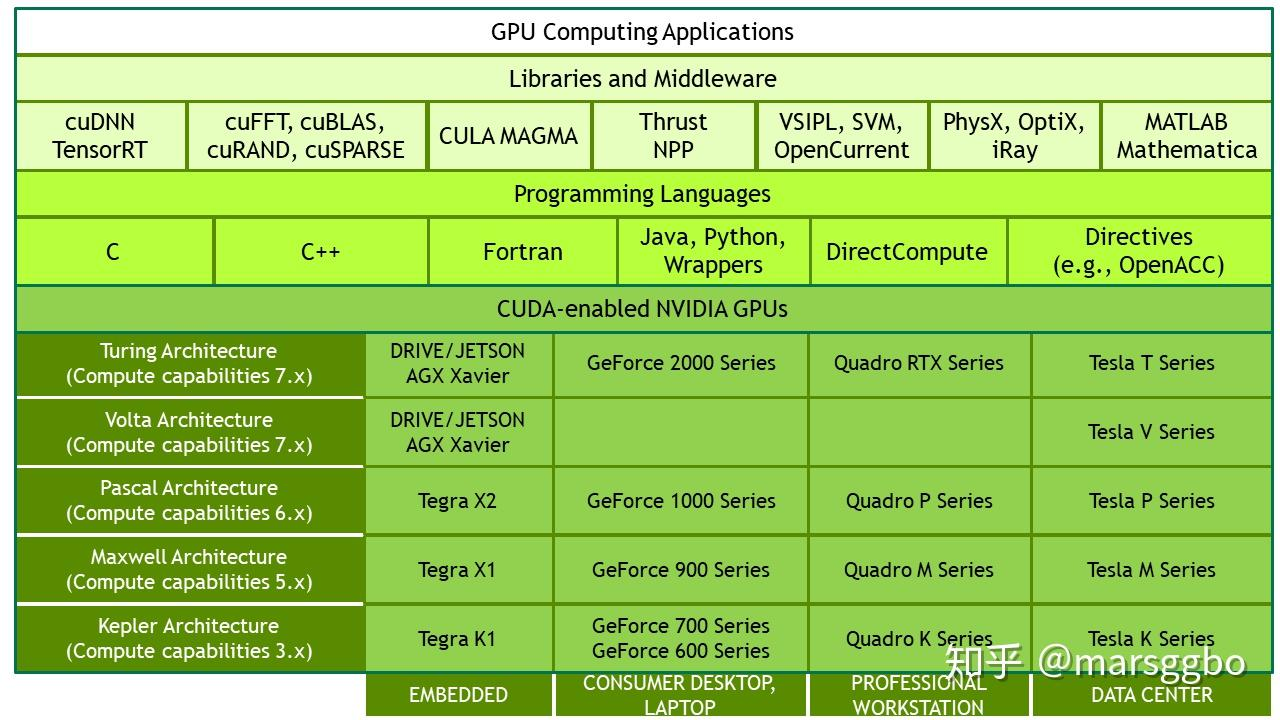
NVIDIA目前的计算平台有:
- Tegra:用于嵌入式
- Geforce:消费产品,笔记本
- Quadro:用于图形领域,工作站
- Tesla:主要用于计算,数据中心
nvidia自己有一套描述GPU计算能力的代码,其名字为计算能力
| 计算能力 | 架构名 |
|---|---|
| 1.x | Tesla |
| 2.x | Fermi |
| 3.x | Kepler |
| 4.x | Maxwell |
| 5.x | Pascal |
| 6.x | Volta |
CPU和GPU都有线程,其区别如下
- CPU线程:重量级实体,操作系统交替执行线程,线程上下文切换开销很大;CPU核设计会尽可能减少一个或两个线程运行时间的延迟
- GPU线程:轻量级,GPU应用一般包含成千上万的线程,多数在排队状态,切换基本没有开销;GPU核设计用于大量线程,最大幅度提高吞吐量
CUDA平台
CUDA平台不是单单指软件或者硬件,而是建立在Nvidia GPU上的一整套平台,并扩展出多语言支持.
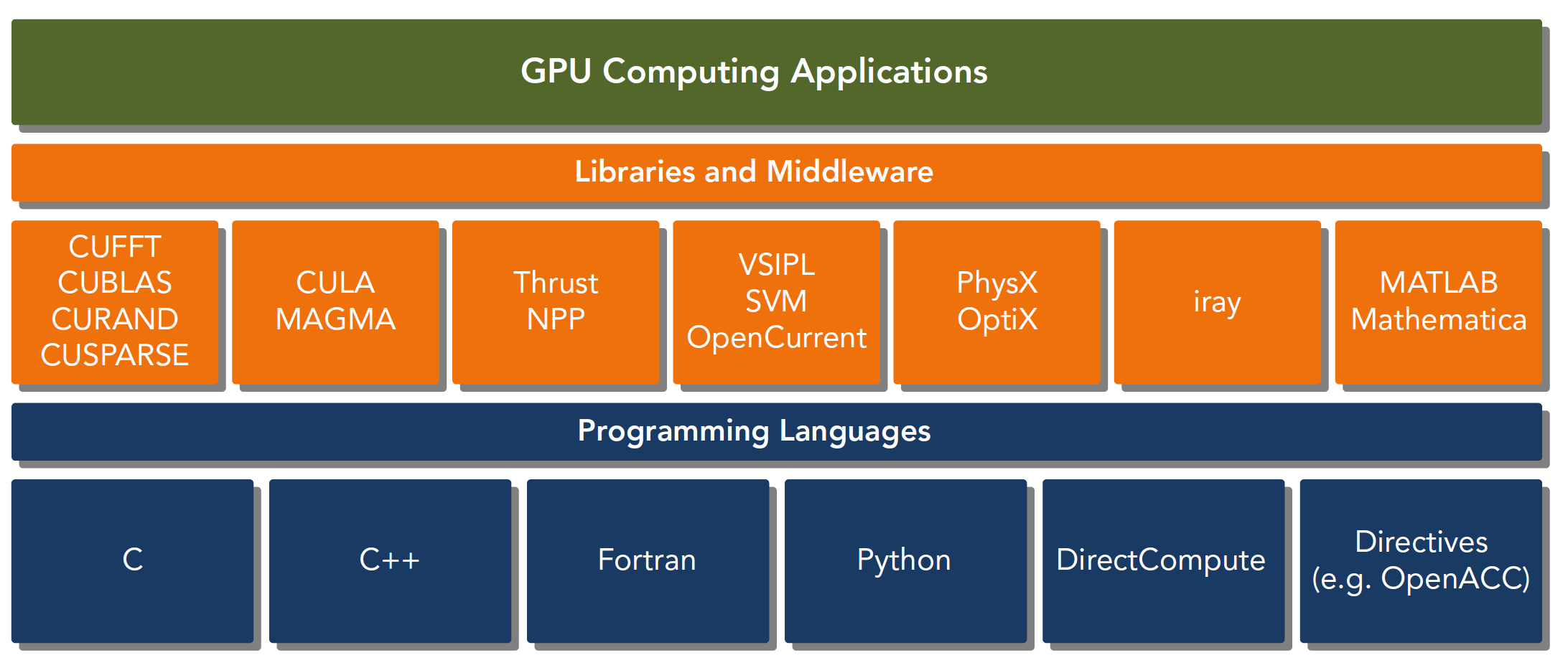
CUDA C 是标准ANSI C语言的扩展,扩展出一些语法和关键字来编写设备端(GPU端)代码,CUDA库本身提供了大量API来操作设备完成计算.
API有两种不同的层次
- CUDA驱动API(底层):使用相对困难
- CUDA运行时API(高层):使用简单,其实现基于驱动API
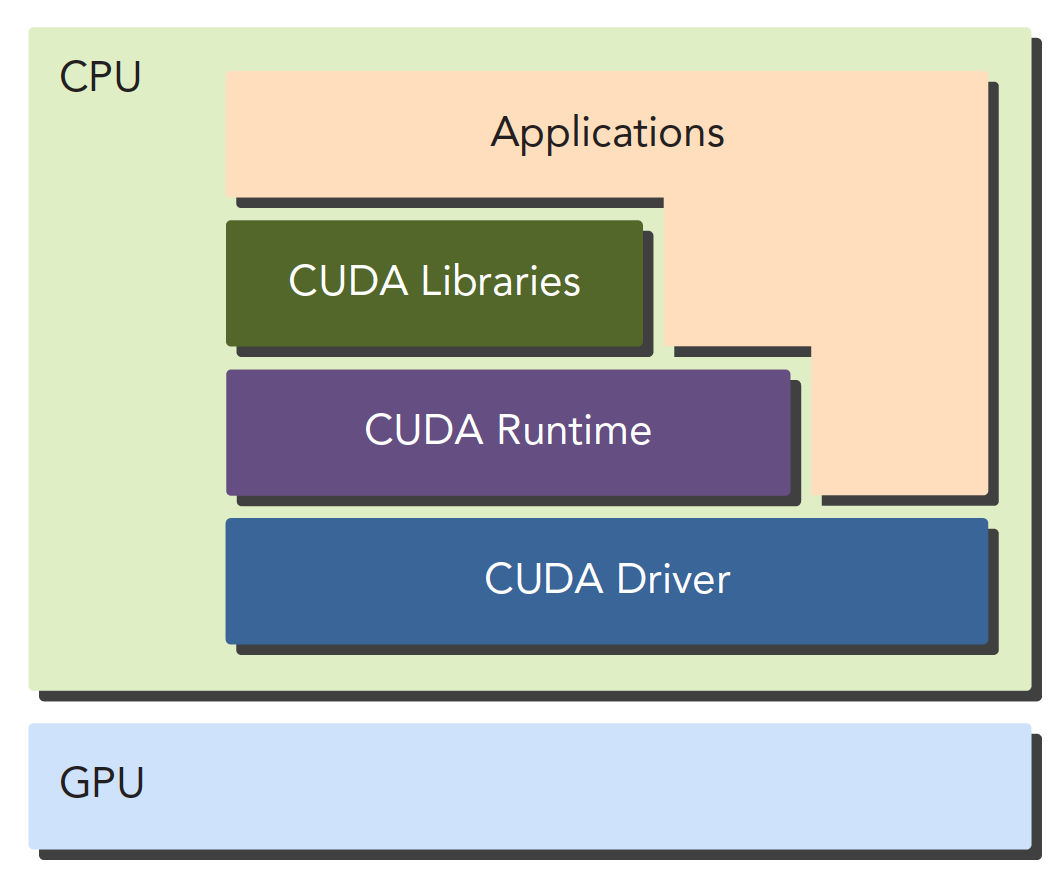
CUDA应用可以分解为两部分,CUDA nvcc编译器会自动分离代码里的不同部分.
- CPU主机端代码:用C编写,用本地C语言编译器编译
- GPU设备端代码(核函数):用
CUDA C编写,用nvcc编译器编译,链接阶段在内核程序调用时添加运行时库.
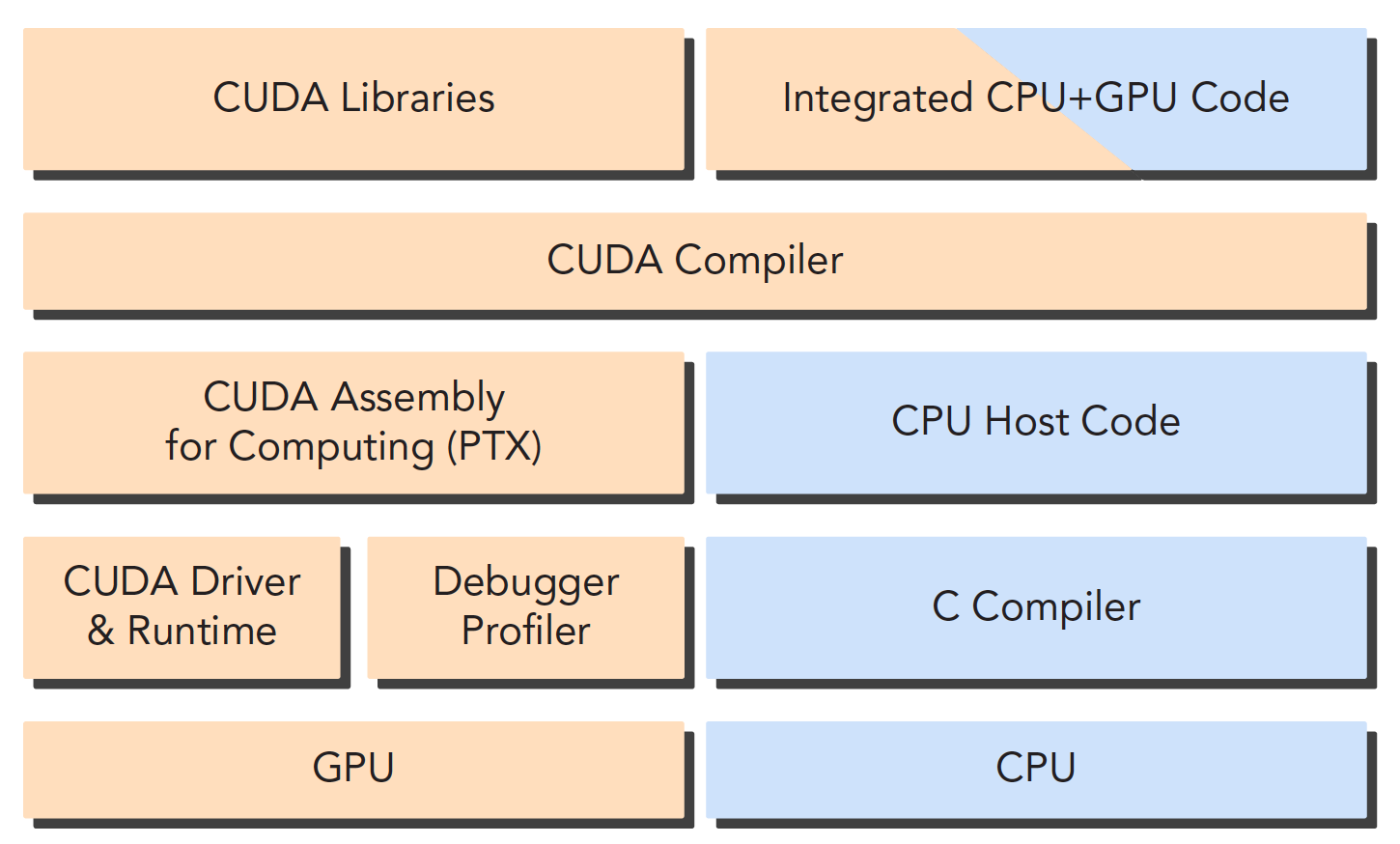
nvcc是从LLVM开源编译系统为基础开发的(所以CUDA也可以用于X86CPU或者别的?)
在CUDA平台之外还存在CUDA工具箱(CUDA Toolkit),包含编译器,数学库,调试优化等工具参考cuda toolkit
- Compiler:NVCC
- Tools:profiler,debuggers等
- Libraries: 部分科学库和实用程序库,包含CUDA Runtime(cudart),cudadevrt(CUDA device runtime),cupti(CUDA profiling tools interface)等.
- CUDA Samples:使用各种CUDA和library API的代码示例
- CUDA Driver:安装CUDA Toolkit的时候会默认安装CUDA Driver
一般cuda程序分为5个步骤
- 分配GPU内存
- 拷贝内存到设备
- 调用CUDA内核来执行计算
- 把数据拷贝回主机端
- 内存销毁
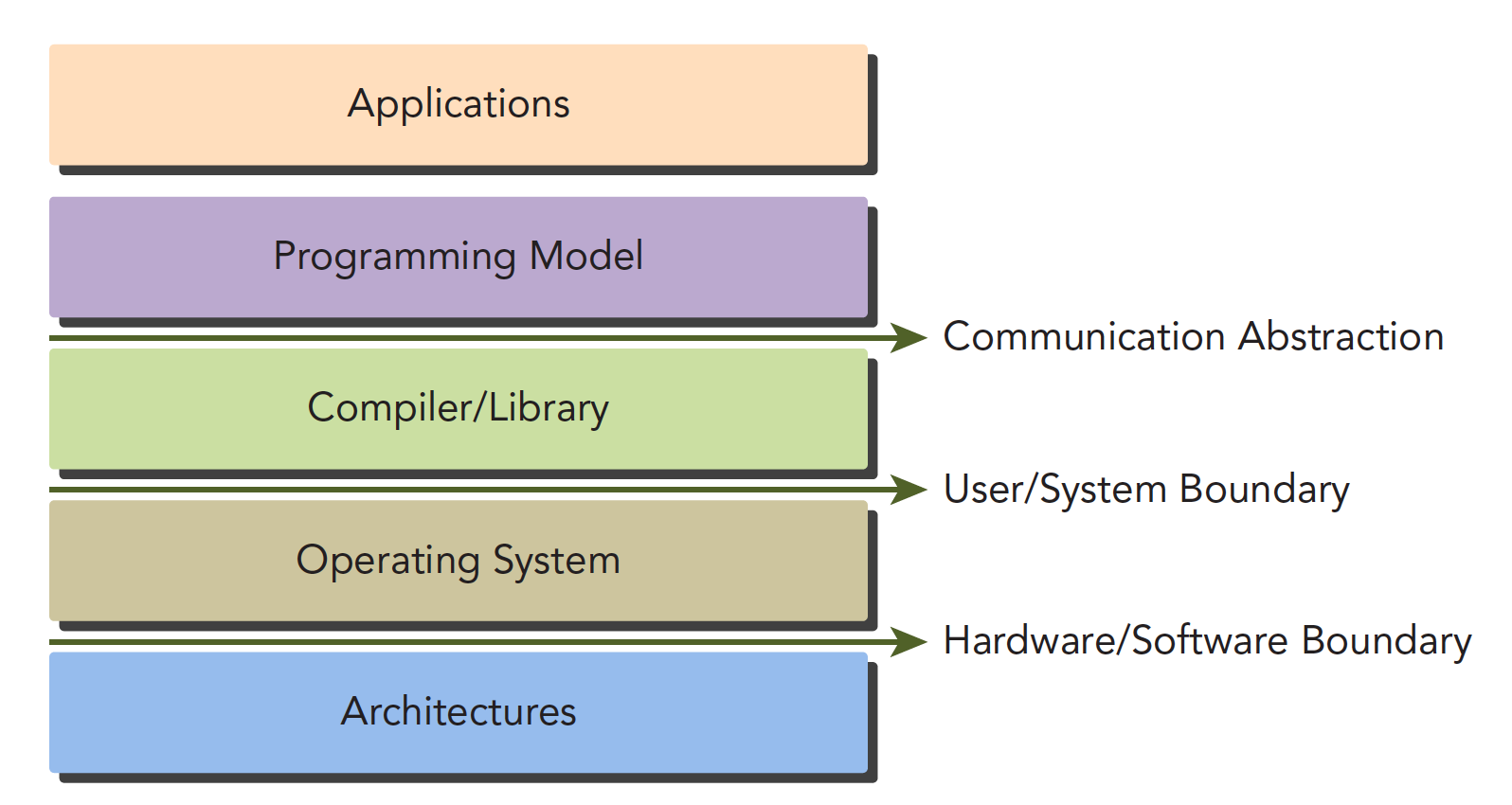
CUDA编程模型
编程模型:语法,内存结构,线程结构等写程序时需要控制的部分(控制异构计算设备工作模式).
通信抽象是编程模型和编译器/库函数的分界线
GPU中的编程模型可以分为
- 核函数
- 内存管理
- 线程管理
- 流
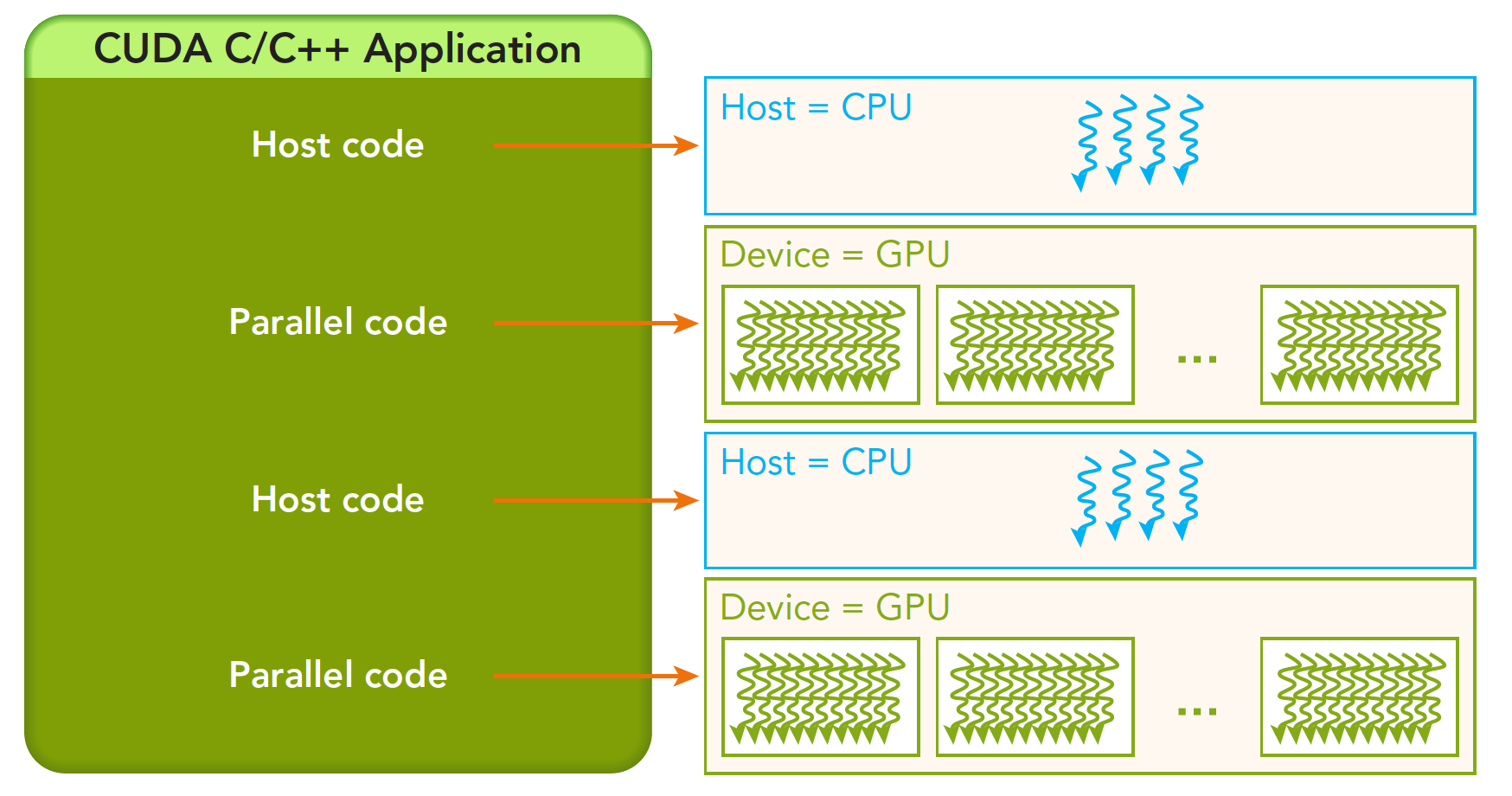
一个完整的CUDA应用的可能执行顺序如下图,从host的串行到调用核函数(核函数被调用后控制马上归还主机线程,也就是在第一个并行代码执行时,很有可能第二段host代码已经开始同步执行了)。
下面的研究层次
- 内存
- 线程
- 核函数
- 启动
- 编写
- 验证
- 错误处理
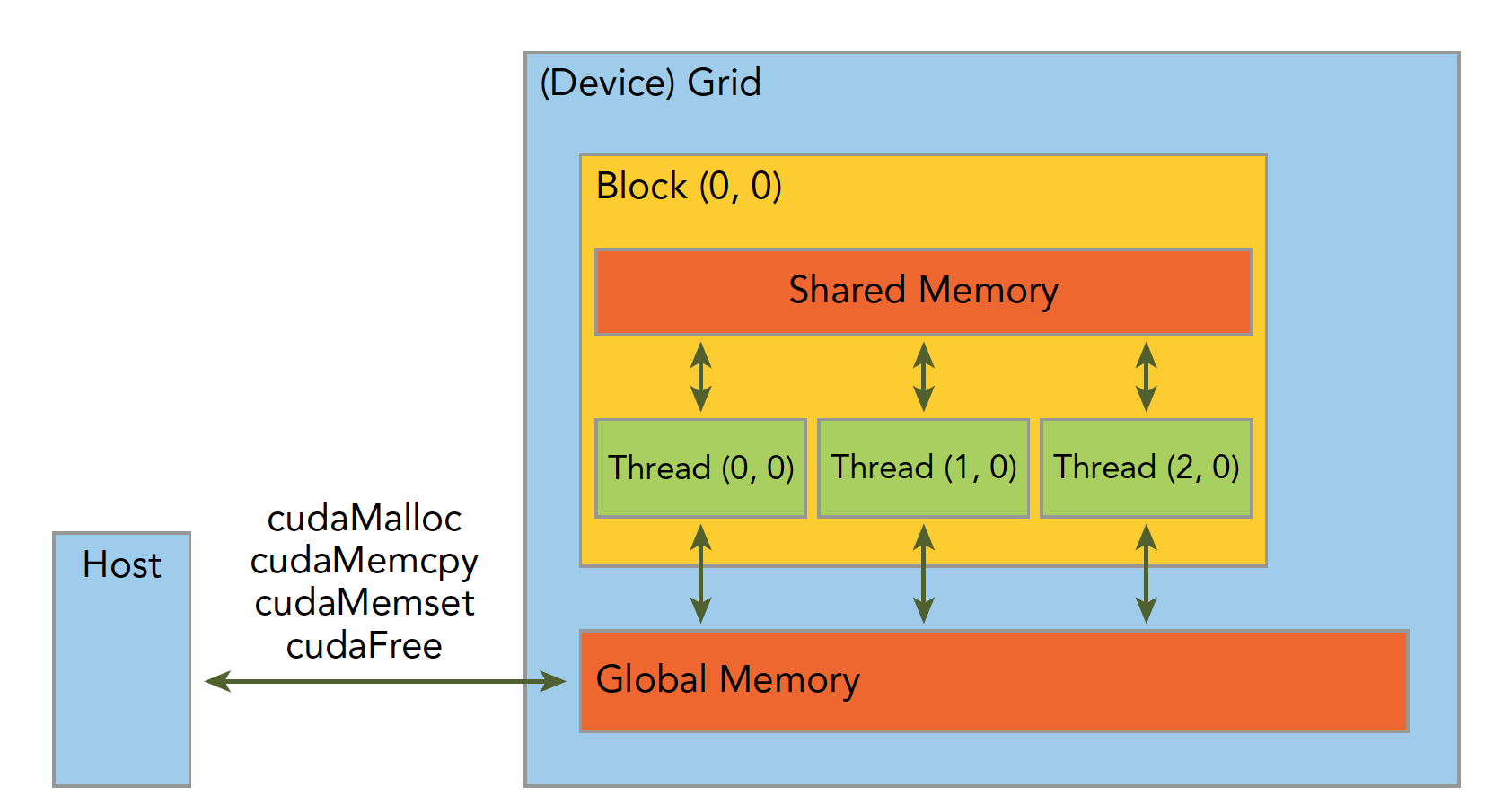
内存管理
- 串行程序:寄存器空间,栈空间内的内存由机器自己管理;堆空间由用户控制分配和释放
- 并行程序:类似
| 标准C函数 | CUDA C 函数 | 说明 |
|---|---|---|
| malloc | cudaMalloc | 内存分配 |
| memcpy | cudaMemcpy | 内存复制 |
| memset | cudaMemset | 内存设置 |
| free | cudaFree | 释放内存 |
线程管理
当内核函数开始执行,如何组织GPU的线程就变成了最主要的问题了.
一个核函数只能有一个grid,一个grid可以有很多个块,每个块可以有很多的线程
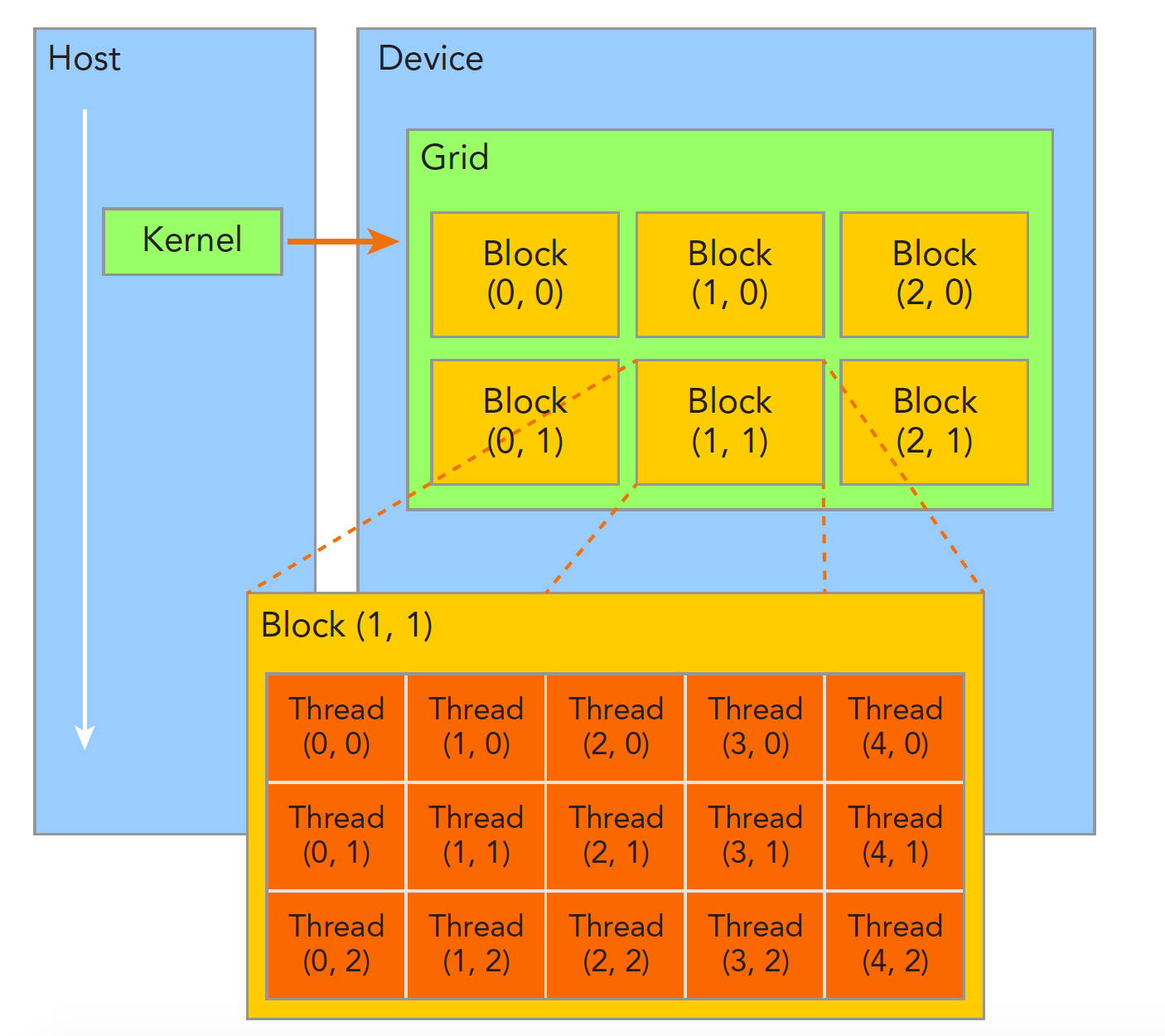
block中的线程可以同步和共享内存,不同block中的线程不能相互影响.
为了让不同的线程对应不同的数据,给这些线程进行编号,用两个内置结构体表示坐标
- blockidx:线程块在线程grid内的位置索引
- threadidx:线程在线程block内的位置索引.(idx=index)
坐标用uint3定义,包含3个无符号整数(x,y,z);比如blockidx.x
范围也用两个结构体表示,也包含3个字段x,y,z
- blockDim
- gridDim
核函数
核函数就是在CUDA模型上诸多线程中运行的那段串行代码,用NVCC编译,产生的机器码是GPU的机器码,所以我们写CUDA程序就是写核函数.
核函数的启动:
kernel_name<<<grid,block>>>(argument list);比如
kernel_name<<<4,8>>>(argument list);表示

//主机等待设备端执行
cudaDeviceSynchronize(void);核函数的编写:
声明核函数的模板
__global__ void kernel_name(argument list);| 限定符 | 执行位置 | 调用方式 | 备注 |
|---|---|---|---|
| global | 设备端执行 | 可以从主机调用也可以从计算能力3以上的设备调用 | 必须有一个void的返回类型 |
| device | 设备端执行 | 设备端调用 | |
| host | 主机端执行 | 主机调用 |
并行程序中经常的一种现象:把串行代码并行化时对串行代码块for的操作,也就是把for并行化.
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int i = 0; i < N; i++)
C[i] = A[i] + B[i];
}
//并行代码
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}错误处理:
#define CHECK(call)\
{\
const cudaError_t error=call;\
if(error!=cudaSuccess)\
{\
printf("ERROR: %s:%d,",__FILE__,__LINE__);\
printf("code:%d,reason:%s\n",error,cudaGetErrorString(error));\
exit(1);\
}\
}编译执行:
nvcc xxxx.cu -o xxxx


